Plongée dans l’IA : Une série de 3 épisodes
Bonjour, je suis Kevin Séjourné, docteur en informatique et ingénieur R&D senior chez Cloud Temple. Comme vous pouvez l’imaginer, depuis 20 ans, j’ai beaucoup écrit de code. Explorateur passionné des LLM, je constate qu’ils peuvent maintenant écrire du code à ma place. Tant mieux ! Mais comme j’ai l’habitude de m’appuyer sur des observations scientifiques, j’ai décidé de tester la qualité de leur travail.
Retrouvez les 3 épisodes de mon étude :
- Épisode 1 : J’automatise mon travail avec les LLM
- Episode 2 : Aidons-nous du LLM pour corriger le code et reconstruire les algorithmes oubliés
- Episode 3 : Complétons le programme initial, testons, testons plus fort
Episode 2 : Aidons-nous du LLM pour corriger le code et reconstruire les algorithmes oubliés
Compilons, et compilons encore
La compilation n’est pas seulement une transformation du code humain vers du binaire interprétable par le CPU, c’est également un analyseur statique de code. La compilation est donc une partie du processus de développement, qui a lieu dès le début. Il est juste étonnant de disposer d’un programme qui a l’air complet et de ne commencer la compilation qu’à ce stade.
Premier aspect, cela ne compile pas, car le compilateur Rust n’est pas installé. Heureusement, GPT4o est généraliste et, si nous lui demandons comment installer Rust sur une KUbuntu 22.04, la réponse avec des commandes apt est précise. sudo apt install rust Précise, mais mentionne un paquet qui n’existe pas, et donc pas d’installation. Malheureusement, les réflexes de Linuxien viennent parfois trop vite, et rapidement la commande est humainement corrigée en sudo aptitude install rust-all avant même d’avoir imaginé la phrase qui viendra expliquer le problème au LLM.
C’est reparti pour `cargo build`, la commande de compilation pour Rust, mais cela ne compile toujours pas. En effet, il y a des erreurs dans le programme. À première vue, des erreurs de type de données et des erreurs de fonctions inexistantes.
Elles auraient pu être détectées plus tôt par VSCode. Une fois Rust installé, c’est VSCode qui détecte le problème et me propose d’installer l’extension Rust-analyser. Rust-analyser permet de détecter beaucoup d’erreurs de compilation directement dans l’environnement de développement et fournit également des suggestions de corrections.
Une fois l’extension installée, il faut se rendre à l’évidence : le programme généré est plein d’erreurs de types et de noms de fonctions hallucinés. Attention, nous disons “hallucinés” ici sans aucune connotation péjorative, c’est juste le terme consacré sur les LLM lorsqu’ils inventent des choses qui n’existent pas. La coloration syntaxique dans VSCode nous permet de parcourir plus facilement le code. Le programme est bien construit, les structures principales semblent présentes, des bibliothèques Rust équivalentes remplacent leurs homologues Python, il n’y a pas d’erreurs de syntaxe évidentes et, en première lecture, l’essentiel du code est présent.
Viens alors pour nous le temps d’apprendre ce langage de programmation, comment les messages d’erreurs à la compilation sont générés. Nous voulons que le LLM corrige ses propres erreurs. Nous allons lui donner les messages d’erreurs et leurs localisations pour lui donner une chance de nous donner le moyen de contournement. Nous allons également monter en compétence sur Rust en lui demandant de justifier ses choix de transformation.
Par exemple, pourquoi ne pas avoir utilisé l’héritage de classe ? Réponse : car l’héritage de classe n’existe pas en Rust, mais est remplacé par le mécanisme plus moderne de Trait.
Comment indiquer au LLM la localisation d’une erreur ? Les LLM sont mauvais avec les nombres, donner un numéro de ligne ne sert à rien. Il est préférable de donner le nom du fichier et de la fonction ou structure suivie du message d’erreur. La plupart du temps, aucune explication n’est requise. Il faut juste mettre bout à bout le nom de fichier, fonction, erreur, et une copie de la ligne en erreur dans la boîte de saisie du chat.
In the definition of “grafana_alert_route” I have there is the following error “no method named `clone` found for struct `RtmsHttpClient` ” for ” let rtms_client = rtms_client.clone();” How do I correct that ?
Les raccords de texte c’est pour faire joli.
Le LLM régénère alors soit le fichier au complet, soit une fonction, soit plusieurs fichiers qu’il faut alors mettre à jour. Il y a de nombreuses erreurs de ce type.
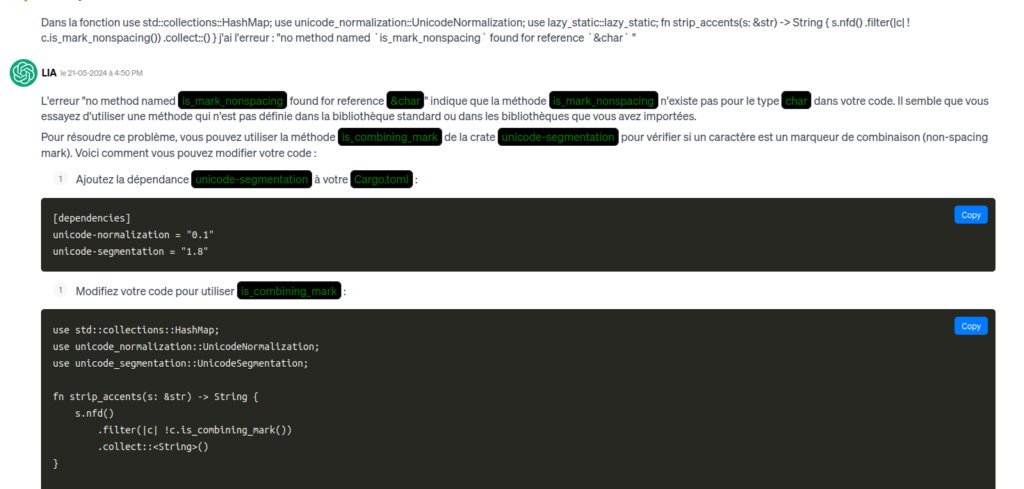
Donc cette phase est assez longue, 8 heures de correction de bugs.
In fine, oh joie ! Un programme compilé, à partir de code généré par un LLM !
Il est alors temps de passer aux tests
Jusqu’ici, nous ne vous avons pas dit de quoi il retourne dans ce programme. Pour des raisons de confidentialité, nous ne pouvons vous en parler, mais cela ne gêne en rien la compréhension de ce qui va suivre.
Nous initialisons l’environnement de test comme pour le programme Python précédent. Nous lançons le programme. Le programme se lance. Le programme (un serveur) se met en attente pour ses premiers appels.
Petite larme à l’œil devant un programme qui fonctionne pour la première fois.
Conformément à la procédure de test, je lance mon appel curl avec l’envoi du premier fichier de test. Le fichier est accepté. Une ligne de log INFO apparaît : 🙂 Une ligne de log ERROR apparaît : 🙁
Un appel de fonction n’a pas l’information requise pour faire l’appel. Une recherche rapide dans le code montre que la variable sensée contenir l’information en question n’est jamais initialisée. Le fichier fourni par le test, qui contient les informations (du JSON), est parsé (transformé en HashMap) mais la HashMap n’est jamais étudiée comme il faut. Le code qui étudie cette HashMap n’est que l’ombre de ce qu’il devrait être.
Debugage avec le LLM
C’est un cas typique de lost-in-the-middle. Toute la partie du code qui était standard a été convertie, les parties qui n’étaient pas standard mais courtes ont aussi été converties car nous les avons demandées explicitement lors de la conversion fichier par fichier. L’algorithme de conversion de données situé dans le fichier le plus long a induit un trop grand nombre de points auxquels le modèle devait faire attention. Ce trop grand nombre implique une simplification du code généré. Un code généré valide, des noms de fonctions valides, une structure valide, les bons commentaires… une transformation des données correcte et jamais vue car très spécifique c’était de trop. Redemander la conversion de ce fichier ne servira à rien, cette partie du code est trop compliquée. Cela fait mal de l’écrire car, d’un point de vue de développeur, ce n’est pas si compliqué. Mais c’est la partie du code qui demande de faire attention aux tenants et aboutissants de tout le reste.
Nous devons donc demander une conversion plus détaillée, morceau de code par morceau de code. Cela implique que nous soyons obligés de progresser un petit peu en Rust pour comprendre en quoi le code généré est adapté au besoin ; notamment si la transformation n’est pas correcte, la première victime est souvent le type des données.
Ici le json en entrée devient, le type dict Python “faiblement typé” puis il est converti en une HashMap<String, String> par le LLM. Ce n’est pas du tout adapté, car un JSON est fondamentalement un arbre de structure associatives. Le LLM “ne comprend pas” ce qu’il fait ; il faut focaliser son attention sur des éléments de code, puis corriger la forme. Là, il n’a pas fait attention à la partie la plus fondamentale de la fonction.
Il faut préciser au LLM le type de la donnée à utiliser pour qu’il puisse se corriger. Nous le forçons sur un serde_json : : value qui est un type fondamental d’encapsulation des JSON en Rust dans les bibliothèques choisies par le LLM. Puis, étape par étape avec GPT4o, nous procédons à la réalisation de la conversion du JSON dans les structures de données correct. Ainsi, nous complétons le code petit à petit. 8 heures pour en arriver jusqu’ici.
Bilan de mi-parcours
Lorsque nous relançons notre test initial, nous pouvons constater le bon fonctionnement du programme dans le cas normal d’utilisation. Mais un développement est composé aussi de sa méthode de déploiement, de tests plus approfondis et de tests de performances. Rendez-vous dans un prochain article.