Immersione nell'IA: una serie di 3 episodi
Salve, sono Kevin Séjourné, dottore di ricerca in informatica e ingegnere senior di R&D presso Cloud Temple. Come potete immaginare, ho scritto molto codice negli ultimi 20 anni. Da appassionato esploratore di LLM, mi sono reso conto che ora possono scrivere codice per me. Tanto meglio! Ma poiché sono abituato a basarmi su osservazioni scientifiche, ho deciso di testare la qualità del loro lavoro.
Guarda i 3 episodi del mio studio:
- Episodio 1: Automatizzare il mio lavoro con gli LLM
- Episodio 2: Utilizziamo LLM per correggere il codice e ricostruire gli algoritmi dimenticati
- Episodio 3: Completamento del programma iniziale, test, test più severi
Episodio 2: Utilizziamo LLM per correggere il codice e ricostruire gli algoritmi dimenticati
Compiliamo e compiliamo ancora un po'.
La compilazione non è solo una trasformazione del codice umano in binario interpretabile dalla CPU, ma è anche un analizzatore statico del codice. La compilazione è quindi una parte del processo di sviluppo, che avviene fin dall'inizio. È incredibile avere un programma che sembra completo e iniziare la compilazione solo in questa fase.
In primo luogo, non verrà compilato, perché l'elemento Ruggine non è installato. Fortunatamente, GPT4o è un generalista e, se gli chiediamo come installare Ruggine su un KUbuntu 22.04la risposta con i comandi apt è preciso. sudo apt install rust Accurato, ma menziona un pacchetto che non esiste, e quindi nessuna installazione. Sfortunatamente, i riflessi di Linuxiano a volte arrivano troppo in fretta, e l'ordine viene rapidamente corretto in modo umano da sudo aptitude install rust-all prima ancora di aver pensato alla frase che spiegherà il problema all'LLM.
Si torna a `cargo build`, il comando di compilazione per Rust, ma ancora non si compila. Ci sono errori nel programma. A prima vista, errori di tipo di dati e di funzioni inesistenti.
Avrebbero potuto essere individuati prima Codice VSC. Una volta installato Rust, è Codice VSC che rileva il problema e suggerisce di installare l'estensione Analizzatore di ruggine. Rust-analyser è in grado di rilevare molti errori di compilazione direttamente nell'ambiente di sviluppo e fornisce anche suggerimenti per le correzioni.
Una volta installata l'estensione, bisogna affrontare la realtà: il programma generato è pieno di errori di tipo e di nomi di funzioni allucinati. Si badi bene, qui diciamo "allucinato" senza alcuna connotazione peggiorativa, è solo il termine usato dai LLM quando inventano cose che non esistono. La colorazione sintattica in Codice VSC ci permette di sfogliare il codice più facilmente. Il programma è ben costruito, le strutture principali sembrano essere presenti e ci sono alcune librerie. Ruggine sostituiscono le loro controparti Python, non ci sono evidenti errori di sintassi e, a una prima lettura, la maggior parte del codice è presente.
Ora è il momento di imparare questo linguaggio di programmazione e come vengono generati i messaggi di errore in fase di compilazione. Vogliamo che l'LLM corregga i propri errori. Gli daremo i messaggi di errore e la loro posizione per dargli la possibilità di fornire una soluzione. Inoltre, aumenteremo le sue competenze in Rust chiedendogli di giustificare le sue scelte di trasformazione.
Ad esempio, perché non avete usato l'ereditarietà delle classi? Risposta: perché l'ereditarietà delle classi non esiste in Rust, ma è sostituita dal più moderno meccanismo dei Trait.
Come si fa a dire all'LLM dove si è verificato un errore? Gli LLM non sono bravi con i numeri, quindi dare un numero di riga è inutile. È preferibile indicare il nome del file e della funzione o struttura, seguito dal messaggio di errore. Nella maggior parte dei casi non è necessaria alcuna spiegazione. È sufficiente inserire il nome del file, la funzione, l'errore e una copia della riga in errore nella casella di input della chat.
Nella definizione di "grafana_alert_route" che ho c'è il seguente errore "no method named `clone` found for struct `RtmsHttpClient` " for " let rtms_client = rtms_client.clone();" Come posso correggere questo errore?
Le giunture del testo sono solo di facciata.
L'LLM rigenera quindi l'intero file, o una funzione, o diversi file che devono essere aggiornati. Esistono molti errori di questo tipo.
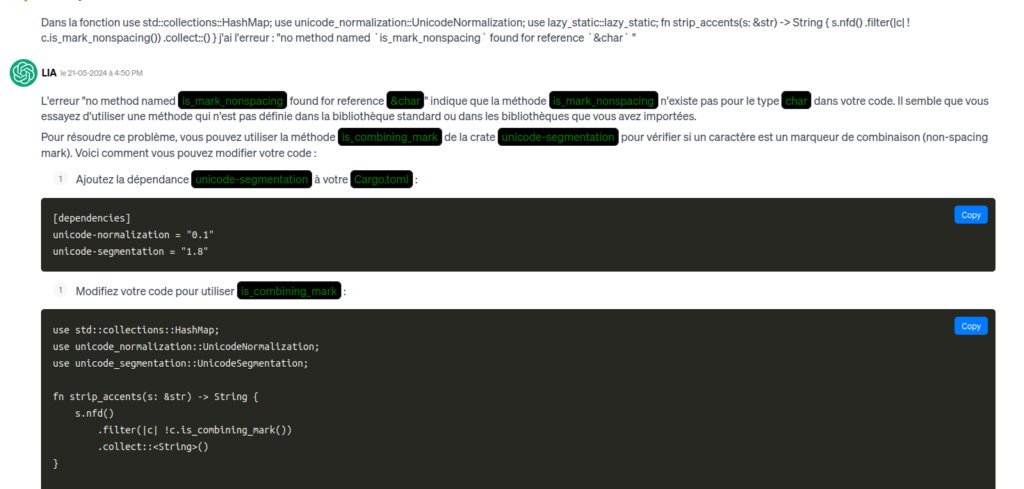
Quindi questa fase è piuttosto lunga, 8 ore di correzione di bug.
Finalmente, oh gioia! Un programma compilato dal codice generato da un LLM!
Poi è il momento dei test
Finora non vi abbiamo detto di cosa tratta questo programma. Per motivi di riservatezza, non possiamo dirvelo, ma ciò non impedisce in alcun modo la comprensione di quanto segue.
Inizializziamo l'ambiente di prova come per il precedente programma Python. Eseguiamo il programma. Il programma viene lanciato. Il programma (un server) attende le prime chiamate.
Una piccola lacrima per un programma che funziona per la prima volta.
In conformità con la procedura di test, faccio la mia telefonata ricciolo con l'invio del primo file di prova. Il file viene accettato. Viene visualizzata una riga di registro INFO: 🙂 Viene visualizzata una riga di registro ERROR: 🙁
Una chiamata di funzione non dispone delle informazioni necessarie per effettuare la chiamata. Una rapida ricerca nel codice mostra che la variabile che dovrebbe contenere le informazioni in questione non viene mai inizializzata. Il file fornito dal test, che contiene le informazioni (dalla variabile JSON), è parsé (trasformato in HashMap) ma il HashMap non è mai stato studiato in modo adeguato. Il codice che studia questo HashMap è solo l'ombra di quello che dovrebbe essere.
Debug con LLM
Questo è un tipico caso di perso nel mezzo. Tutta la parte del codice che era standard è stata convertita, le parti che non erano standard ma brevi sono state convertite perché le abbiamo richieste esplicitamente durante la conversione file per file. L'algoritmo di conversione dei dati nel file più lungo ha prodotto un numero eccessivo di punti a cui il modello ha prestato attenzione. Questo numero eccessivo ha reso necessaria una semplificazione del codice generato. Un codice generato valido, nomi di funzioni validi, una struttura valida, i commenti giusti... una trasformazione dei dati corretta che non era mai stata vista prima perché era così specifica era troppo. Chiedere di nuovo la conversione di questo file non servirà a nulla, questa parte del codice è troppo complicata. Fa male scriverla perché, dal punto di vista dello sviluppatore, non è poi così complicata. Ma questa è la parte del codice che richiede di prestare attenzione ai dettagli di tutto il resto.
Dobbiamo quindi richiedere una conversione più dettagliata, pezzo per pezzo di codice. Questo significa che dobbiamo progredire un po' a Rust per capire come il codice generato si adatta alle esigenze; in particolare, se la trasformazione non è corretta, la prima vittima è spesso il tipo di dati.
Qui il json diventa l'ingresso dettatura Pitone "e poi convertito in un HashMap<StringaString> da parte dell'LLM. Questo è del tutto inadatto, in quanto un JSON è fondamentalmente un albero di strutture associative. L'LLM 'non capisce' cosa sta facendo; deve concentrare la sua attenzione sugli elementi del codice, quindi correggere la forma. In questo caso, non ha prestato attenzione alla parte più fondamentale della funzione.
L'LLM ha bisogno di sapere quale tipo di dati utilizzare per potersi correggere. Lo costringiamo a usare un serde_json : : valore che è un tipo di incapsulamento fondamentale per JSON in Rust nelle librerie scelte dal LLM. Poi, passo dopo passo, con GPT4o, convertiamo il file JSON nelle strutture dati corrette. Quindi stiamo completando il codice un po' alla volta. 8 ore per arrivare a questo punto.
Revisione intermedia
Quando rieseguiamo il nostro test iniziale, possiamo vedere che il programma funziona bene nel caso d'uso normale. Ma lo sviluppo è costituito anche dal metodo di distribuzione, da test più approfonditi e da test di performance. Ci vediamo in un prossimo articolo.