


Diving into AI: A series of 3 episodes
Hi, I'm Kevin Séjourné, PhD in computer science and senior R&D engineer at Cloud Temple. As you can imagine, I've been writing a lot of code over the last 20 years. As a passionate explorer of LLMs, I've realised that they can now write code for me. So much the better! But as I'm used to relying on scientific observations, I decided to test the quality of their work.
Watch the 3 episodes of my study :
- Episode 1: I automate my work with LLMs
- Episode 2: Let's use LLM to correct the code and rebuild forgotten algorithms
- Episode 3: Completing the initial programme, testing, testing harder
Episode 2: Let's use LLM to correct the code and rebuild forgotten algorithms
Let's compile, and compile some more
Compilation is not only a transformation of human code into binary that can be interpreted by the CPU, it is also a static code analyser. Compilation is therefore a part of the development process, which takes place right from the start. It's just amazing to have a program that looks complete and only start compiling at this stage.
First, it won't compile, because the Rust is not installed. Fortunately, GPT4o is a generalist and, if we ask it how to install Rust on a KUbuntu 22.04the answer with commands apt is precise. sudo apt install rust Accurate, but mentions a package that doesn't exist, and therefore no installation. Unfortunately, the reflexes of Linuxian sometimes come too quickly, and the order is quickly corrected humanely by sudo aptitude install rust-all before you've even thought of the sentence that will explain the problem to the LLM.
It's back to `cargo build`, the compilation command for Rust, but it still won't compile. There are errors in the program. At first sight, data type errors and non-existent function errors.
They could have been detected earlier by VSCode. Once Rust is installed, it's VSCode which detects the problem and suggests that I install the extension Rust-analyser. Rust-analyser can detect many compilation errors directly in the development environment and also provides suggestions for corrections.
Once you've installed the extension, you have to face facts: the program generated is full of type errors and hallucinated function names. Mind you, we say 'hallucinatory' here without any pejorative connotation, it's just the term used by LLMs when they invent things that don't exist. The syntactic colouring in VSCode allows us to browse the code more easily. The programme is well constructed, the main structures seem to be present, and there are some libraries. Rust equivalents replace their Python counterparts, there are no obvious syntax errors and, on first reading, most of the code is present.
Now it's time to learn this programming language and how compile-time error messages are generated. We want the LLM to correct its own errors. We're going to give it the error messages and their locations to give it a chance to give us a workaround. We're also going to increase its Rust skills by asking it to justify its transformation choices.
For example, why didn't you use class inheritance? Answer: because class inheritance doesn't exist in Rust, but is replaced by the more modern Trait mechanism.
How do I tell the LLM where an error has occurred? LLMs are bad with numbers, so giving a line number is useless. It is preferable to give the name of the file and the function or structure followed by the error message. Most of the time, no explanation is required. Just put the file name, function, error and a copy of the line in error in the chat input box.
In the definition of "grafana_alert_route" I have there is the following error "no method named `clone` found for struct `RtmsHttpClient` " for " let rtms_client = rtms_client.clone();" How do I correct that ?
Text splices are just for show.
The LLM then regenerates either the entire file, or a function, or several files which then have to be updated. There are many errors of this type.
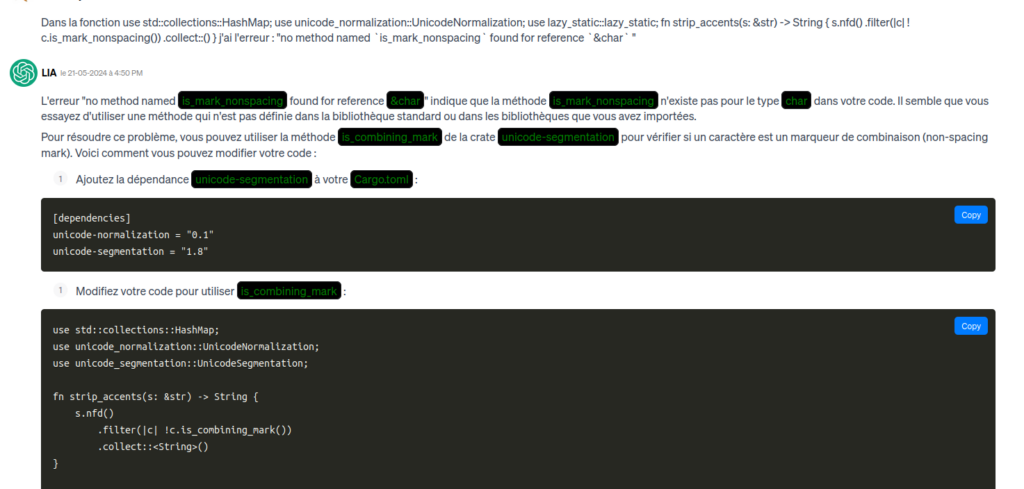
So this phase is quite long, 8 hours of bug-fixing.
Finally, oh joy! A program compiled from code generated by an LLM!
Then it's time for the tests
So far, we haven't told you what this programme is about. For reasons of confidentiality, we can't tell you, but that in no way hinders your understanding of what follows.
We initialise the test environment as for the previous Python program. We run the program. The program launches. The program (a server) waits for its first calls.
A little tear for a programme that's working for the first time.
In accordance with the test procedure, I make my call curl with the sending of the first test file. The file is accepted. An INFO log line appears: 🙂 An ERROR log line appears: 🙁
A function call does not have the information required to make the call. A quick search of the code shows that the variable that is supposed to contain the information in question is never initialised. The file supplied by the test, which contains the information (from the JSON), is parsé (transformed into HashMap) but the HashMap is never properly studied. The code that studies this HashMap is only a shadow of what it should be.
Debugging with LLM
This is a typical case of lost-in-the-middle. All the part of the code that was standard was converted, the parts that were not standard but short were also converted because we explicitly requested them during the file-by-file conversion. The data conversion algorithm in the longest file resulted in too many points for the model to pay attention to. This excessive number meant that the generated code had to be simplified. Valid generated code, valid function names, a valid structure, the right comments... a correct data transformation that had never been seen before because it was so specific was too much. Asking for this file to be converted again won't do any good, this part of the code is too complicated. It hurts to write it because, from a developer's point of view, it's not that complicated. But this is the part of the code that requires you to pay attention to the ins and outs of everything else.
We therefore have to request a more detailed conversion, piece by piece of code. This means that we have to progress a little in Rust to understand how the generated code is adapted to the need; in particular, if the transformation is not correct, the first victim is often the data type.
Here the json input becomes the dictation Python "and then converted into a HashMap<StringString> by the LLM. This is completely unsuitable, as a JSON is basically a tree of associative structures. The LLM 'doesn't understand' what it's doing; it needs to focus its attention on elements of the code, then correct the form. In this case, it hasn't paid attention to the most fundamental part of the function.
The LLM needs to be told what type of data to use so that it can correct itself. We force it to use a serde_json : : value which is a fundamental type of encapsulation for JSON into Rust in the libraries chosen by the LLM. Then, step by step with GPT4o, we convert the JSON in the correct data structures. So we're completing the code bit by bit. 8 hours to get this far.
Mid-term review
When we re-run our initial test, we can see that the programme works well in the normal use case. But development is also made up of its deployment method, more in-depth tests and performance tests. See you in a future article.