Eintauchen in die KI: Eine dreiteilige Serie
Hallo, ich bin Kevin Séjourné, Doktor der Informatik und Senior R&D Engineer bei Cloud Temple. Wie Sie sich vorstellen können, habe ich in den letzten 20 Jahren viel Code geschrieben. Als leidenschaftlicher Erforscher von LLMs stelle ich fest, dass sie nun Code an meiner Stelle schreiben können. Umso besser! Aber da ich mich gewöhnlich auf wissenschaftliche Beobachtungen stütze, habe ich beschlossen, die Qualität ihrer Arbeit zu testen.
Sehen Sie sich die drei Episoden meiner Studie an :
- Episode 1: Ich automatisiere meine Arbeit mit LLMs
- Episode 2: Lassen Sie uns mit Hilfe der LLM den Code korrigieren und vergessene Algorithmen rekonstruieren.
- Episode 3: Vervollständigen wir das ursprüngliche Programm, testen wir, testen wir härter
Episode 2: Lassen Sie uns mit Hilfe der LLM den Code korrigieren und vergessene Algorithmen rekonstruieren.
Kompilieren, und noch mehr kompilieren
Die Kompilierung ist nicht nur eine Umwandlung von menschlichem Code in eine von der CPU interpretierbare Binärform, sondern auch ein statischer Parser für den Code. Die Kompilierung ist also ein Teil des Entwicklungsprozesses, der von Anfang an stattfindet. Es ist nur erstaunlich, wenn man ein Programm hat, das vollständig aussieht, und erst jetzt mit der Kompilierung beginnt.
Erster Aspekt, es kompiliert nicht, da der Compiler Rust nicht installiert wird. Glücklicherweise ist GPT4o generalistisch und wenn wir ihn fragen, wie man Folgendes installiert Rust auf einer KUbuntu 22.04Die Antwort mit Befehlen apt ist präzise. sudo apt install rust Präzise, erwähnt aber ein Paket, das es nicht gibt, und daher keine Installation. Leider sind die Reflexe von Linuxer kommen manchmal zu schnell, und schnell wird die Bestellung menschlich korrigiert, indem sudo aptitude install rust-all bevor man sich überhaupt den Satz ausgedacht hat, der der LLM das Problem erklären soll.
Es geht wieder los mit `cargo build`, dem Kompilierungsbefehl für Rust, aber es kompiliert immer noch nicht. Tatsächlich gibt es einige Fehler im Programm. Auf den ersten Blick Fehler beim Datentyp und Fehler bei nicht vorhandenen Funktionen.
Sie hätten früher entdeckt werden können durch VSCode. Sobald Rust installiert ist, ist es VSCode der das Problem erkennt und mir vorschlägt, die Erweiterung zu installieren Rust-analyser. Rust-analyser ermöglicht es, viele Kompilierfehler direkt in der Entwicklungsumgebung zu entdecken und liefert auch Vorschläge für Korrekturen.
Sobald Sie die Erweiterung installiert haben, müssen Sie sich den Tatsachen stellen: Das erzeugte Programm ist voll von Typenfehlern und halluzinierten Funktionsnamen. Achtung, wir sagen hier "halluziniert" ohne jede pejorative Konnotation, es ist nur der auf LLMs übliche Ausdruck, wenn sie Dinge erfinden, die es nicht gibt. Die syntaktische Färbung in VSCode ermöglicht es uns, den Code leichter zu durchsuchen. Das Programm ist gut aufgebaut, die Hauptstrukturen scheinen vorhanden zu sein, Bibliotheken Rust ersetzen ihre Python-Pendants, es gibt keine offensichtlichen Syntaxfehler und beim ersten Lesen ist der Großteil des Codes vorhanden.
Wir wollen diese Programmiersprache lernen und erfahren, wie Fehlermeldungen beim Kompilieren erzeugt werden. Wir wollen, dass die LLM ihre eigenen Fehler korrigiert. Wir werden ihm die Fehlermeldungen und ihre Lokalisierung geben, damit er eine Chance hat, uns den Weg zur Umgehung zu zeigen. Außerdem werden wir seine Kompetenz in Bezug auf Rust steigern, indem wir ihn bitten, seine Transformationsentscheidungen zu begründen.
Warum wurde zum Beispiel keine Klassenvererbung verwendet? Antwort: Weil es in Rust keine Klassenvererbung gibt, sondern diese durch den moderneren Mechanismus von Trait ersetzt wird.
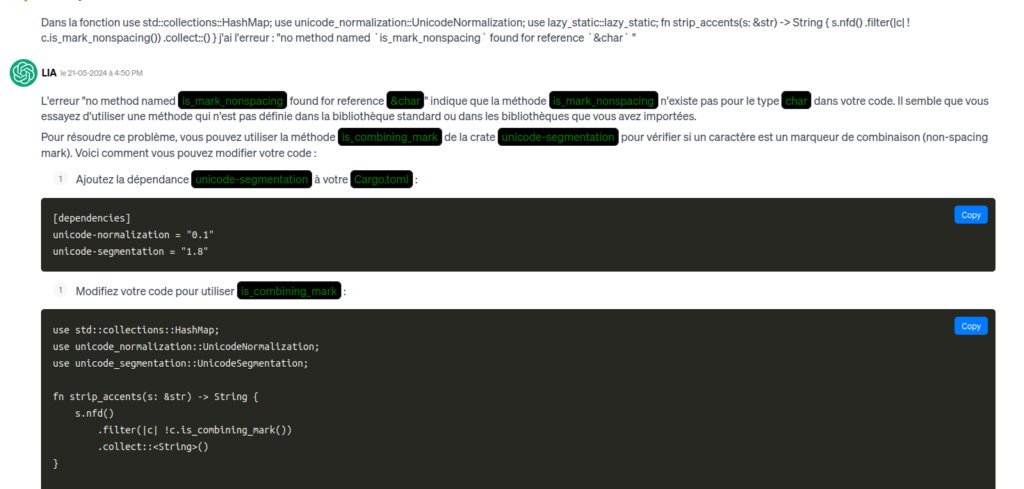
Wie teilt man der LLM mit, wo sich ein Fehler befindet? LLMs können schlecht mit Zahlen umgehen, eine Zeilennummer anzugeben, ist nicht hilfreich. Besser ist es, den Namen der Datei und der Funktion oder Struktur gefolgt von der Fehlermeldung anzugeben. In den meisten Fällen ist keine Erklärung erforderlich. Man muss nur den Dateinamen, die Funktion, den Fehler und eine Kopie der fehlerhaften Zeile in der Chat-Eingabebox aneinanderreihen.
In der Definition von "grafana_alert_route" habe ich folgenden Fehler "no method named `clone` found for struct `RtmsHttpClient` " for " let rtms_client = rtms_client.clone();". Wie kann ich das korrigieren?
Textverbindungen sind nur zur Verschönerung da.
Die LLM regeneriert dann entweder die gesamte Datei, eine Funktion oder mehrere Dateien, die dann aktualisiert werden müssen. Es gibt viele solcher Fehler.
Diese Phase ist also ziemlich lang, acht Stunden lang werden Fehler behoben.
In fine, oh Freude! Ein kompiliertes Programm, aus Code, der von einer LLM generiert wurde!
Dann ist es Zeit für die Tests
Bisher haben wir Ihnen nicht gesagt, worum es in diesem Programm geht. Aus Gründen der Vertraulichkeit können wir Ihnen nichts darüber sagen, aber das stört nicht das Verständnis des Folgenden.
Wir initialisieren die Testumgebung wie beim vorherigen Python-Programm. Wir starten das Programm. Das Programm wird gestartet. Das Programm (ein Server) hält sich für seine ersten Aufrufe bereit.
Kleine Träne im Auge bei einem Programm, das zum ersten Mal funktioniert.
Gemäß dem Testverfahren starte ich meinen Anruf curl mit dem Senden der ersten Testdatei. Die Datei wird angenommen. Eine INFO-Logzeile erscheint: 🙂 Eine ERROR-Logzeile erscheint: 🙁.
Einem Funktionsaufruf fehlt die Information, die benötigt wird, um den Aufruf zu tätigen. Eine schnelle Suche im Code zeigt, dass die Variable, die die fragliche Information enthalten soll, nie initialisiert wird. Die vom Test bereitgestellte Datei, die die Informationen (vom JSON), ist parsé (umgewandelt in HashMap), sondern die HashMap wird nie richtig untersucht. Der Code, der diese untersucht HashMap nur ein Schatten dessen ist, was er sein sollte.
Debugging mit der LLM
Dies ist ein typischer Fall von lost-in-the-middle. Der gesamte Teil des Codes, der Standard war, wurde konvertiert. Die Teile, die nicht Standard, aber kurz waren, wurden ebenfalls konvertiert, da wir sie bei der dateiweisen Konvertierung explizit angefordert hatten. Der Algorithmus zur Datenumwandlung, der sich in der längsten Datei befand, führte zu einer zu großen Anzahl von Punkten, auf die das Modell achten musste. Diese zu große Anzahl bedeutet, dass der generierte Code vereinfacht werden muss. Ein gültiger generierter Code, gültige Funktionsnamen, eine gültige Struktur, die richtigen Kommentare ... eine korrekte und nie gesehene, weil sehr spezifische Datenumwandlung war zu viel. Die Konvertierung dieser Datei erneut anzufordern, wird nichts bringen, dieser Teil des Codes ist zu kompliziert. Es tut weh, das zu schreiben, denn aus der Sicht eines Entwicklers ist es gar nicht so kompliziert. Aber es ist der Teil des Codes, bei dem man auf die Hintergründe von allem anderen achten muss.
Wir müssen also eine detailliertere Umwandlung verlangen, Code-Stück für Code-Stück. Das bedeutet, dass wir gezwungen sind, ein wenig in Rust zu lernen, um zu verstehen, inwiefern der erzeugte Code den Anforderungen entspricht; insbesondere wenn die Umwandlung nicht korrekt ist, ist das erste Opfer oft der Datentyp.
Hier die json in der Eingabe wird, wird der Typ dict Python "schwach typisiert" und wird dann in eine HashMap<String, String> durch die LLM. Dies ist völlig ungeeignet, da ein JSON ist im Grunde ein Baum mit assoziativen Strukturen. Der LLM "versteht" nicht, was er tut; seine Aufmerksamkeit muss auf Teile des Codes gerichtet werden, und dann muss die Form korrigiert werden. Hier hat er nicht auf den grundlegendsten Teil der Funktion geachtet.
Wir müssen dem LLM sagen, welchen Datentyp er verwenden soll, damit er sich selbst korrigieren kann. Wir zwingen ihn auf einen serde_json : : value die eine grundlegende Art der Einkapselung von JSON in Rust in den vom LLM ausgewählten Bibliotheken. Dann wird Schritt für Schritt mit GPT4o die Umwandlung des JSON in den korrekten Datenstrukturen. So vervollständigen wir den Code nach und nach. 8 Stunden, um bis hierher zu kommen.
Halbzeitbilanz
Wenn wir unseren ursprünglichen Test erneut starten, können wir feststellen, dass das Programm im normalen Anwendungsfall gut funktioniert. Eine Entwicklung besteht aber auch aus ihrer Einsatzmethode, weitergehenden Tests und Leistungstests. Wir sehen uns in einem der nächsten Artikel.